基础概念

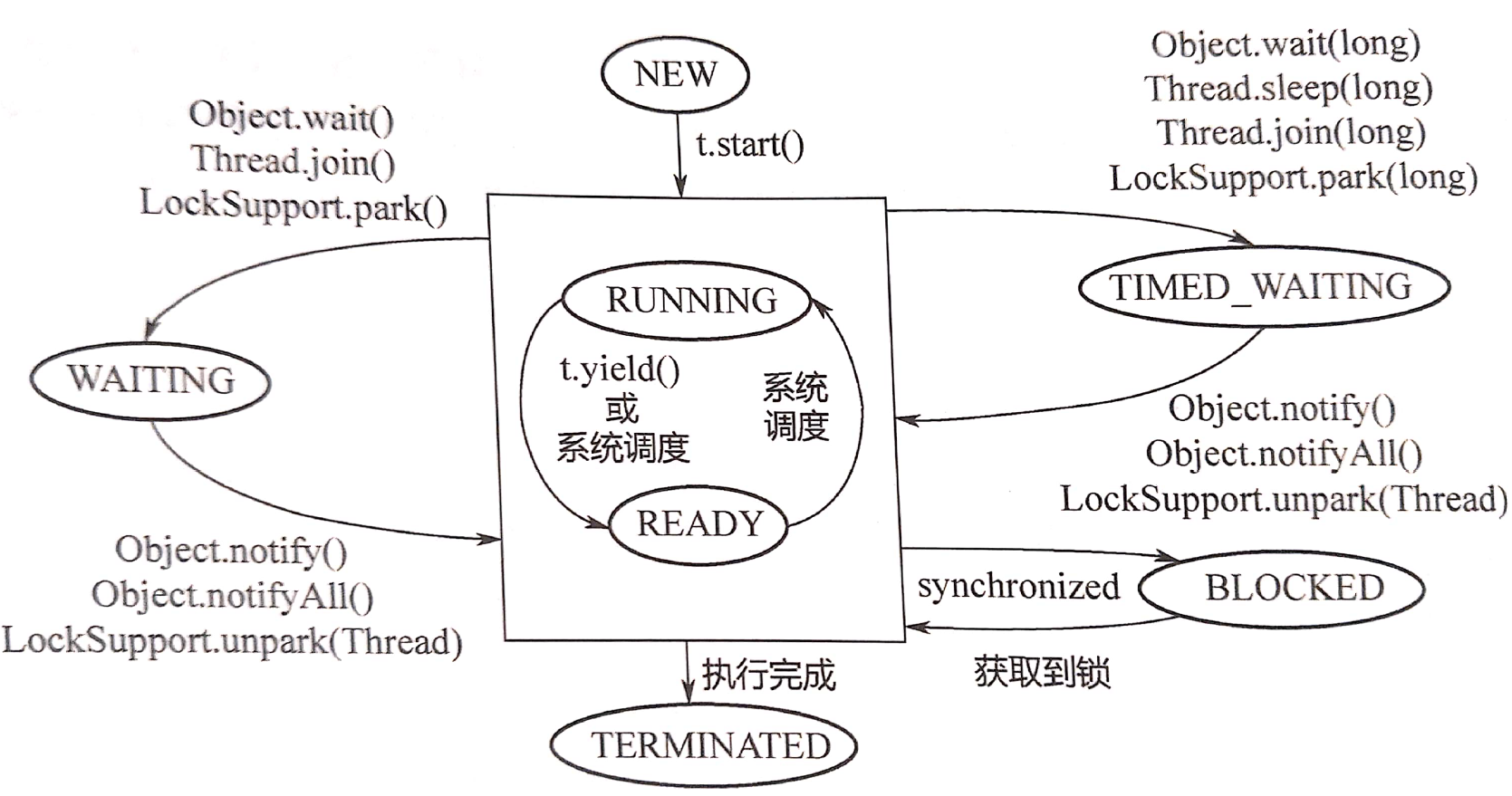
- Java线程获取CPU是协同式而非抢占式。
- 线程关闭:不建议使用stop()/destory()关闭一个运行中的线程。合理的方法是使其运行完,释放资源再退出,如果是循环运行的线程,就使用线程间通信机制,通过主线程通知其退出。
- 用户线程:默认或thread.setDaemon(false),当所有的非守护线程退出后,整个JVM进程就退出。
- 守护线程:thread.setDaemon(true),守护线程不影响整个JVM的退出。
- 退出线程循环:对声明了会抛出InterruptedException的函数调用interrupt()函数设置interrupted标志位,可唤醒轻量级阻塞。
- 轻量级阻塞:能够被中断的阻塞被成为轻量级阻塞,对应的线程状态是waiting和timed_waiting。
- 重量级阻塞:不能够被中断的阻塞被成为重量级阻塞,对应的线程状态是blocked。
- Thread.interrupted():判断当前线程的interrupted标志位状态,并重置该标志位。
- thread.isInterrupted():判断指定线程的interrupted标志位状态。
- synchronized关键字:本质是给某个对象加锁。对于非静态成员函数,锁加在a对象上,对于静态成员函数,锁加在类A.class对象上。
- 实现原理:在Java对象头中的Mark Word数据中有两个字段,锁标志位和占用该锁的thread ID。
- wait()与notify():
- 需要和synchronized一起使用:一个线程调用该对象的wait(),另一个线程调用该对象的notify(),该对象本身就需要同步。
- 线程wait()时需要释放锁,然后进入阻塞状态;线程wait()后被其他线程用notify()唤醒,需要重新拿锁。
- volatile关键字:用于保证64位写入的原子性、内存可见性(写完之后立即对其他线程可见)和禁止重排序。
- 实现原理:x86平台上,在volatile写操作后加入StoreLoad屏障。
- 重排序:CPU有自己的缓存,指令执行顺序和写入主内存的顺序不完全一致。
- as-if-serial语义:对于每个线程,编译器和CPU能够保证其内部看似完全串行。
- happen-before:JMM确保如果A在B之前执行,则A的执行结果必须对B可见,此性质具有传递性。
- 单线程的每个操作,happen-before于该线程中任意后续操作。
- 对volatile变量的写,happen-before于后续对这个变量的读。
- 对synchronized的解锁,happen-before于后续对这个锁的加锁。
- 对final field的写,happen-before后续对final field所在对象的读,对final field所在对象的读,happen-before于后续对final field的读。
- 无锁编程:
- 一写一读的无锁队列:内存屏障
- 一写多读的无锁队列:volatile关键字
- 多写多读的无锁队列:CAS。链表有一个头指针head和一个尾指针tail。,入队列通过对tail进行CAS操作完成,出队列通过对head进行CAS操作完成。
- 无锁栈:只需要对head指针进行CAS操作就可实现入栈和出栈。
- 无锁链表
- Unsafe类:Java不能直接访问操作系统底层,而是通过本地方法来访问,Unsafe类提供了硬件级别的原子操作。主要功能包括:
- 分配与释放内存。
- 定位对象某字段的内存位置,修改对象的字段值。
- 线程的阻塞park()与唤醒unpark()
- CAS操作(compareAndSwapInt/Long/Object)
public native boolean compareAndSwapInt(Object obj, long offset, int expect, int update);
// obj:需要执行CAS操作的对象
// offset:obj中整型field的偏移量
// expect:希望field中存在的值
// update:如果expect与field值相同,设置field为update新值
// 如果field值更改成功则返回true
Atomic类
- AtomicInteger、AtomicLong、AtomicBoolean、AtomicReference:使用Unsafe提供的CAS操作实现。
- ABA问题:当前线程在做CAS操作时,另一个线程将变量的值从A改为B再改回A,会认为数据未发生过改变。要解决ABA问题需要同时比较值和版本号。
- AtomicStampedReference:用于解决ABA问题。
- AtomicMarkableReference:版本号是boolean类型而非整型的累加变量,不能完全避免ABA问题,只能降低ABA发生的概率。
- AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater:对于一个已有的类,在不能更改其源代码的情况下,想要实现对其成员变量的原子操作。首先通过newUpdater静态函数传入要修改的类和对应成员变量的名字,通过反射机制,将类的成员变量包装成一个对象,要修改某个对象的成员变量的值时,再向其中传入相应的对象。之后使用CAS操作实现。
- AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray:针对数组中一个元素的操作是原子的。
- Striped64:用于在高并发环境中计数,其思想是在竞争激烈的时候尽量分散竞争。维护一个base Count和一个Cell数组,计数线程首先会试图更新base Count,如果成功则退出计数,否则认为当前竞争激烈,通过线程计算Hash,将不同的线程分散到不同的Cell数组的index上,然后这个线程的计数内容就会保存在该Cell的位置上面。最后总计数需要结合base Count以及散落在Cell数组中的计数内容。
- LongAdder、LongAccumulator、DoubleAdder、DoubleAccumulator都继承自Striped64。
- 伪共享和缓存行填充:每个CPU都有自己的缓存,缓存与主内存进行交换的基本单位是Cache Line,同一个Cache Line的数据会一起被失效,即使它可能未被修改,即伪共享。缓存行填充使这些数据分散到不同的Cache Line中。
Lock与Condition
- AQS(AbstractQueuedSynchronizer,队列同步器):是一个抽象类,为构造同步器提供一种通用的机制。包含以下三个主要组成部分:
- 内部状态:具体含义根据实现类而不同,会被并发的修改,因此所有修改状态的方法都要保证线程安全。
- 双向链表队列:用于存放等待的线程。入队就是把新Node加入tail后面,然后对tail进行CAS操作;出队就是对head进行CAS操作,然后把head向后移一个位置。
- 由协作工具类实现的获取/释放等方法。
- 可重入锁:当一个线程调用object.lock()获得锁进入互斥区后,再次调用object.lock()仍然可以拿到该锁,以避免发生死锁。JUC包中的锁都是可重入锁。
- 公平锁:多个线程按照申请顺序去获得锁,线程会进入队列去排队,只有队首线程能获得锁。
- 非公平锁:新到达的线程直接尝试获取锁,通过避免唤醒过程的开销和时间消耗来提高效率。
- 获取独占锁:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
// 1. tryAcquire:尝试获取锁,是一个虚函数,可以在此实现公平/非公平锁、可重入/不可重入锁
// 2. addWaiter:获取锁未成功时,为当前线程生成一个Node并将其放入队列尾部。
// 3. acquireQueue:调用park阻塞当前线程,当线程被唤醒且在队列头部时尝试获取锁并出队列,返回true表示被阻塞期间有其他线程向它发送过中断信号。
// 4. selfInterrupt:将自己的中断标志位设为true,对阻塞期间收到却未响应的中断信号进行补偿
- 释放独占锁:锁的拥有者释放独占锁并唤醒队列中的后继者。
- 可中断锁:如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,B不想等待了,想先处理其他事情,可以中断它。
- 实现原理:当收到中断信号后不再阻塞,直接抛出InterruptedException跳出for循环。
- 读写锁:读线程与读线程不用互斥。当使用ReadWriteLock时,并不直接使用,而是获得其内部的ReadLock和WriteLock,然后分别调用lock/unlock。ReadLock和WriteLock实际上是同一把锁的两个视图。
- 实现原理:将state的低16位用来记录写锁,高16位用来记录读锁(如果使用两个变量无法用一次CAS操作)
- Condition:功能与wait/notify类似,必须与Lock一起使用。使用await/signal避免了wait/notify的生成者通知生成者、消费者通知消费者的问题。
- await()实现原理:线程已经拿到了锁,调用await()操作,将线程加入Condition的等待队列;线程先释放锁再进入阻塞;线程被唤醒后重新拿锁,若是被中断唤醒则抛出中断异常,awaitUninterruptibly()不会响应中断异常。
- signal()实现原理:线程已经拿到了锁,调用signal()操作,唤醒队列中的首个进程。调用unpark前先把线程Node放入互斥锁的同步队列里。
- StampedLock:读的过程中也允许获取写锁后写入。首先进行不加锁的乐观读,如果读出来发现数据被修改了(版本号不同,也用state表示)就升级为悲观读,对于悲观读和悲观写的方法与可重入读写锁效果一样。
同步工具类
Semaphore
- 信号量,提供了资源数量的并发访问控制。当资源个数为1时退化为排他锁。
- 基于AQS,使用acquire获取,使用release释放。
CountDownLatch
- 计数锁,多个线程都可以等待,当计数归零后唤醒所有等待的线程。
- 基于AQS,使用await阻塞,使用countDown减少计数。
CyclicBarrier
- 可重复使用屏障,对进程可进行多次同步。
- 基于ReentrantLock+Condition,使用await阻塞。
Exchanger
- 交换器,用于线程间交换数据。传递当前线程要交换的数据,接收其他线程交换来的数据。
Phaser
- 可以将其看成一个一个的阶段,每个阶段都有需要执行的线程任务,任务执行完毕就进入下一个阶段。所以Phaser特别适合使用在重复执行或者重用的情况。
并发容器
BlockingQueue/Deque
- BlockingQueue:需要入队时若队列已满,就阻塞调用者;需要出队时若队列为空,就阻塞调用者。
- ArrayBlockingQueue:一个用数组实现的环形队列(数组、头指针、尾指针),一个ReentrantLock,一个非空Condition,一个非满Condition。
- LinkedBlockingQueue:基于单向链表,队头和队尾分开操作,使用2个指针2把锁。
- PriorityBlockingQueue:按照元素的优先级从小到大出队列。
- DelayQueue:按延迟时间(未来要执行的时间-当前时间)从小到大出队的PriorityQueue。
- SynchronousQueue:本身没有容量,put()后线程阻塞直到另外一个线程调用take()两个线程才同时解锁。
- LinkedBlockingDeque:基于双向链表,其他和LinkedBlockingQueue一样。
CopyOnWrite
- 在写的时候不直接写回原处,而是把数据拷贝一份进行修改,再通过悲观锁或乐观锁的方式写回。这样可以在读的时候不加锁。
- CopyOnWriteArrayList、CopyOnWriteArraySet。
ConcurrentLinkedQueue
- ConcurrentLinkedQueue是一个单向链表,基于CAS,通过head/tail指针记录头部和尾部。
ConcurrentHashMap
- 在JDK1.8中由数组+链表+红黑树构成。如果其头结点是Node类型,则尾随一个链表;如果头结点是TreeNode类型,则尾随一个红黑树。链表中的元素超过某个阈值时变为红黑树,红黑树的元素个数小于某个阈值时再转换为链表。
- 使用红黑树:当一个槽里有很多元素时,查询和更新速度比链表快很多,Hash冲突的问题能够较好解决。
- 加锁的粒度:对每个头结点分别加锁。
- 并发扩容:比较复杂,但是支持。
ConcurrentSkipListMap
- ConcurrentHash是一种key无序的HashMap,ConcurrentSkipListMap是一种key有序的HashMap。使用跳表而非红黑树实现。
线程池与Future
- 线程池的优势:
- 消耗:通过重复利用已创建的线程降低线程创建和销毁所造成的消耗。
- 速度:当任务到达时,可以不需要等到线程创建就能立即执行。
- 管理:方便对线程统一分配、调优和监控。
- 线程池使用生产者消费者模型,调用方不断地向任务队列中提交任务,有一组线程不断地从队列中取出任务。实现线程池需要考虑以下四个问题:
- 如何设置队列的长度。
- 如何设置线程池中线程的个数。
- 提交的新任务如何处理。
- 当没有任务时,线程是睡眠&轮询还是阻塞&唤醒。(通常基于阻塞队列实现)
ThreadPoolExecutor
- 核心数据结构:
- 持有一个存放任务的
BlockingQueue<Runnable>。 - 持有一个用于互斥访问控制的ReentrantLock。
- 持有一个存放线程的
HashSet<Worker> Worker是ThreadPoolExecutor的内部类,继承自AQS,实现了Runnable接口,封装了线程、接收到的任务、执行完毕的任务个数。
- 持有一个存放任务的
// 核心配置参数
public ThreadPoolExecutor(int corePoolSize, // 在线程池中始终维护的线程个数
// 在线程全部被占用且队列已满时候扩充线程数至该值
int maximumPoolSize,
// 当线程空闲时间超过此值,总线程数收缩回corePoolSize
long keepAliveTime,
// 时间单位
TimeUnit unit,
// 存放任务的阻塞队列
BlockingQueue<Runnable> workQueue,
// 线程工厂
ThreadFactory threadFactory,
// 当线程池不可再扩充且队列已满时的拒绝策略
RejectedExecutionHandler handler ) {
}
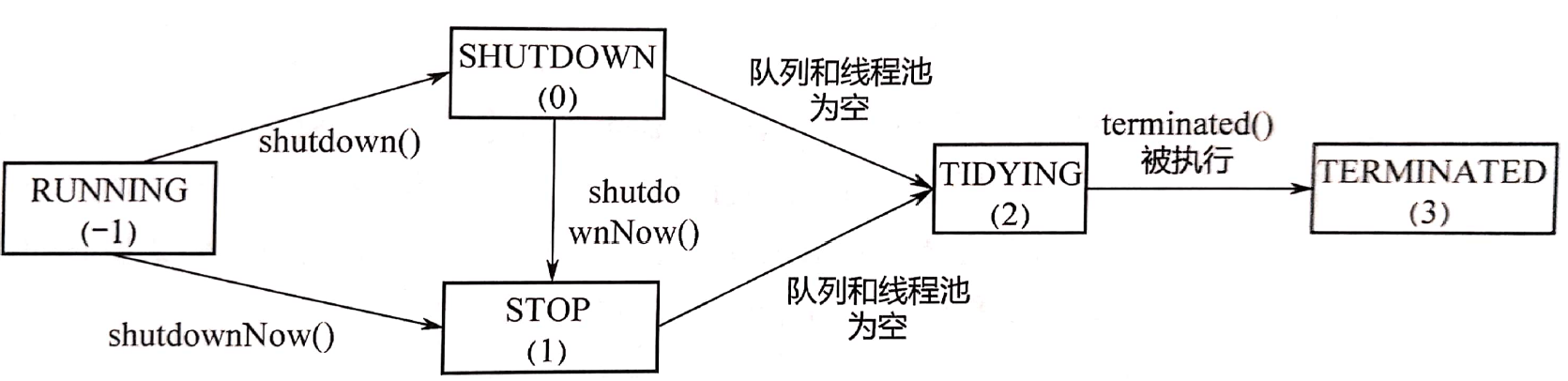
- 线程池的五种状态
- RUNNING:线程池能够接收新任务,能对已接收的任务进行处理。
- SHUTDOWN:线程池不能接收新任务,能对已接收的任务进行处理。
- STOP:线程池不能接收新任务,不能对已接收的任务进行处理。
- TIDYING:线程池的所有任务都已终止。
- TERMINATED:线程池彻底终止。
- 任务提交流程:
- 判断当前线程数是否大于或等于corePoolSize,如果小于则新建线程执行,如果大于,则进入2。
- 判断队列是否已满,如果未满则放入,如果已满则进入3。
- 判断当前线程数师傅大于或等于maxPoolSize,如果小于则新建线程执行,如果大于则进入4.
- 根据拒绝策略拒绝任务。
- 任务执行流程:Worker不断从队列中取出Runnable任务调用run()执行。
- 线程池的四种拒绝策略:
- 让调用者直接在自己的线程里执行,线程池不做处理。
- 线程池直接抛出异常(默认策略)。
- 线程池直接把任务丢掉,当作什么也没发生。
- 线程池把队列头任务删除,把该任务放入队列中。
Callable&Future
- Callable是一个使用Runnable实现的有返回值的接口,自定义一个Callable后向线程池submit,会立刻返回一个Future。当调用者通过Future获取结果时,如果任务没有计算完,则调用者阻塞在此处。
- 线程池内部线程调用Callable的call方法,转换为Runnable的run(),将结果赋值给FutureTask对象的outcome字段,外部线程通过get()获取outcome,如果还未执行完就park()
ScheduledThreadPoolExecutor
- 按时间调度来执行任务,有两种方式:
- 延迟执行任务:推迟任务执行时间,依靠DelayQueue,实现原理是二叉堆。
- 按周期执行任务:AtFixedRate按固定频率执行任务,WithFixedDelay按固定间隔执行任务。执行完一个任务后再把该任务放回任务队列中。
ThreadLocal:https://blog.csdn.net/qq_42862882/article/details/89820017
Java.Object中有哪些方法:https://www.cnblogs.com/lingcheng7777/p/11738510.html