持久化
- 两种方式:
- RDB(Redis DataBase):保存某一个时间点之前的数据。
- 在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件。
- 通过配置参数(在 redis.conf 配置文件中的 SNAPSHOTTING 下)或在客户端执行bgsave命令进行触发。
- RDB(Redis DataBase):保存某一个时间点之前的数据。
# 表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 900 1
- AOF(Append-only file):保存Redis服务器端执行的每一条命令。
- 将“操作 + 数据”以格式化指令的方式追加到操作日志文件的尾部,在append操作返回后(已经写入到文件或者即将写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当server需要数据恢复时,可以直接replay此日志文件,即可还原所有的操作过程。
RDB
文件结构
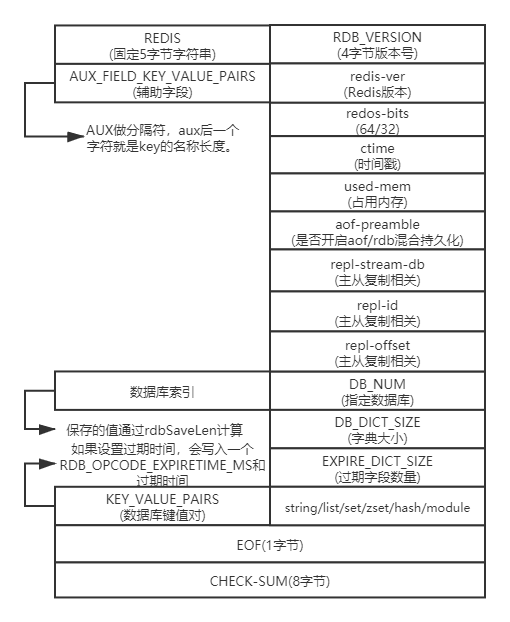
- opcodes:区分加载的字段类型。在每一部分前面都有一个类型字节。

- 数据库键值对的结构:
- EXPIRE_TIME:可选。根据具体的键是否有过期时间决定,该字段固定为8个字节。
- LRU或者LFU:可选。根据配置的内存淘汰算法决定。LRU算法保存秒级别的时间戳,LFU算法只保存counter的计数(0~255,1字节)。
- VALUE_TYPE:值类型。Redis数据类型和底层编码结构。
- KEY:键。键保存为字符串。
- 保存形式1:length+string
- length:字符串长度。变长字段。
- string:具体内容
- 保存形式2:按整型保存
- type:表明存储的整数类型
- int:字符串的整数表示
- 保存形式3:将字符串进行LZF压缩之后保存
- type:表明存储的类型
- compress_len:压缩之后的长度
- original_len:压缩之前原始字符串的长度
- data:保存具体的LZF压缩之后的数据
- 保存形式1:length+string
- VALUE:值。值根据数据类型和编码结构保存为不同的形式,共有九种值类型。
- 字符串类型:同键的保存
- 列表的保存:列表在Redis中编码为quicklist结构,从整体看是一个双向链表,但链表的每个节点在Redis中编码为zipList结构,ziplist结构在一块连续的内存中保存,并且保存时可以选择进行LZF压缩或者不压缩。
- quicklist节点数:同length字段
- 未压缩每个ziplist按字符串保存,压缩了则按lzf保存。
- 集合的保存:集合类型在Redis中有两种编码方式:一种为intset,另一种为Hash。
- intset:在Redis中也是一块连续的内存,直接将intset按字符串保存。
- Hash:第一个字段为字典的大小,接下来逐字段保存字典的键。
- 有序集合的保存:有序集合类型在Redis中也有两种编码方式:一种为ziplist,另一种为skiplist。
- ziplist:将ziplist整体作为一个字符串保存。
- skiplist:第一个字段为skiplist包含的元素个数,接着分别按元素和元素的分值依次保存。元素保存为字符串,元素分值保存为一个双精度浮点数类型(固定为8个字节)。
- 散列的保存:散列类型也有两种编码方式,一种为ziplist,一种为Hash。
- ziplist:编码方式的保存同有序集合。
- Hash:第一个字段为散列表的大小,然后依次保存键值对,键值都保存为字符串类型。
- Stream的保存:
bgsave
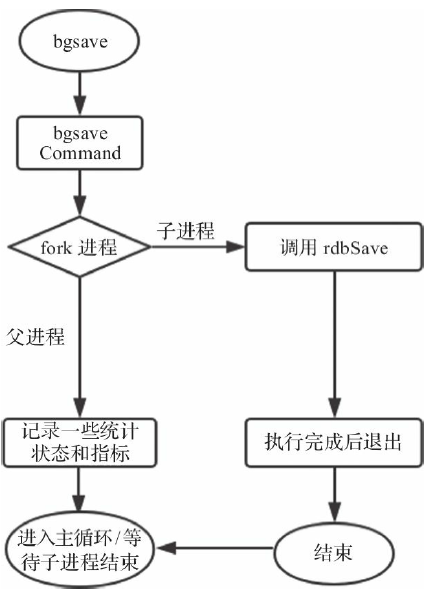
优势和劣势
- 优势:
- 每隔一段时间全量备份
- 灾备简单,可以远程传输
- 子进程备份的时候,主进程不会有任何io操作(写入修改或删除),保证备份数据的完整性。
- 相对AOF来说,当有更大文件的时候可以快速重启恢复。
- 劣势:
- 发生故障时,有可能会丢失最后一次的备份数据。
- 子进程所占用的内存比会和父进程一模一样,会造成CPU负担
- 由于定时全量备份是重量级操作,所以无法处理实时备份。
- 总结:适合大量数据的恢复,但是数据的完整性和一致性可能会不足。
AOF
- Redis一般会同时开启AOF和RDB。
- RDB保存的是一个时间点的快照,那么如果Redis出现了故障,丢失的就是从最后一次RDB执行的时间点到故障发生的时间间隔之内产生的数据。如果Redis数据量很大,QPS很高,那么执行一次RDB需要的时间会相应增加,发生故障时丢失的数据也会增多。
- AOF的速度是RDB速度的一半(如果做了AOF重写会加快)。
命令同步
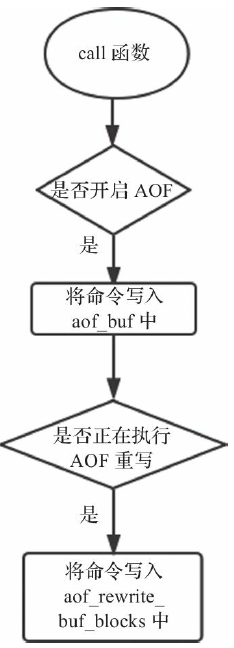
- 如果开启了AOF,则每条命令执行完毕后都会同步写入aof_buf中,aof_buf是个全局的SDS类型的缓冲区。
- Redis通过catAppendOnlyGenericCommand函数将命令转换为保存在缓冲区中的数据结构。
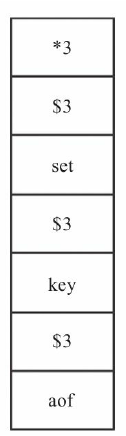
- 首先以*3开始,表示命令共有3个参数。$3表示接下来的第1个参数长度为3,顺序读取第3个字符set,第1个参数就解析完毕。以此类推,第2个$3表示第2个参数的长度,读取为key,第3个$3表示第3个参数的长度aof。至此,该条命令解析完毕。读取到下一个*时即表明开启了其他命令的解析。
文件写入
- 通过操作系统提供的write函数执行。但是write之后数据只是保存在kernel的缓冲区中,真正写入磁盘还需要调用fsync函数。fsync是一个阻塞并且缓慢的操作,所以Redis通过appendfsync配置控制执行fsync的频次。
- no:不执行fsync,由操作系统负责数据的刷盘。数据安全性最低但Redis性能最高。
- always:每执行一次写入就会执行一次fsync。数据安全性最高但会导致Redis性能降低。
- everysec:每1秒执行一次fsync操作。属于折中方案,在数据安全性和性能之间达到一个平衡。
重写
- 为了解决AOF文件体积膨胀的问题,Redis提供了AOF重写功能:Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个文件所保存的数据库状态是相同的,但是新的AOF文件不会包含任何浪费空间的冗余命令,通常体积会较旧AOF文件小很多。
- AOF重写通过fork出一个子进程来执行,重写不会对原有文件进行任何修改和读取,子进程对所有数据库中所有的键各自生成一条相应的执行命令,最后将重写开始后父进程继续执行的命令进行回放,生成一个新的AOF文件。
- 自动触发:
# 当AOF文件大于64MB时,并且AOF文件当前大小比基准大小增长了100%时会触发一次AOF重写
# 起始的基准大小为Redis重启并加载完AOF文件之后,aof_buf的大小。当执行完一次AOF重写之后,基准大小相应更新为重写之后AOF文件的大小。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
- 手动触发:bgrewriteaof
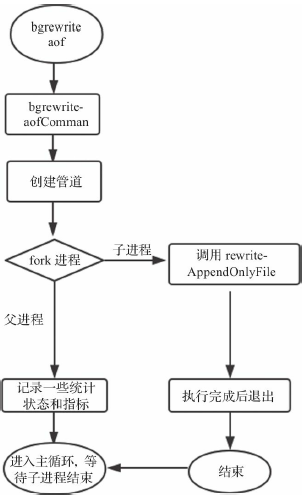
- 混合持久化指进行AOF重写时子进程将当前时间点的数据快照保存为RDB文件格式,而后将父进程累积命令保存为AOF格式。
- 加载时,首先会识别AOF文件是否以REDIS字符串开头,如果是,就按RDB格式加载,加载完RDB后继续按AOF格式加载剩余部分。
优势和劣势
- 优势:
- AOF更加耐用,可以以秒级别为单位备份,如果发生问题,也只会丢失最后一秒的数据,大大增加了可靠性和数据完整性。
- 以log日志形式追加,如果磁盘满了,会执行redis-check-aof工具。
- 当数据太大的时候,redis可以在后台自动重写aof。当redis继续把日志追加到老的文件中去时,重写也是非常安全的,不会影响客户端的读写操作。
- AOF日志包含所有的写操作,会更加便于redis的解析恢复。
- 劣势:
- 相同的数据,同一份数据,AOF比RDB大。
- 针对不同的同步机制,AOF会比RDB慢,因为AOF每秒都会备份做写操作,这样相对于RDB来说就略低。
- 较为复杂,发生过数据恢复时不完整的bug。
RDB和AOF的比较
- 如果能接受一段时间的缓存丢失,可以使用RDB。
- 如果更关心实时性的数据,可以使用AOF
- 使用RDB和AOF结合一起做持久化,RDB做冷备,可以在不同时期对不同版本做恢复,AOF做热备,保证数据仅仅只有1秒的损失。当AOF破损不可用了,再用RDB恢复,这样就做到了两者的相互结合。(也就是说Redis恢复会先加载AOF,如果AOF有问题会再加载RDB,这样就达到冷热备份的目的)
主从复制
基本概念
- 目的:
- 读写分离:单台服务器能支撑的QPS是有上限的,我们可以部署一台主服务器、多台从服务器,主服务器只处理写请求,从服务器通过复制功能同步主服务器数据,只处理读请求,以此提升Redis服务能力;另外我们还可以通过复制功能来让主服务器免于执行持久化操作:只要关闭主服务器的持久化功能,然后由从服务器去执行持久化操作即可。
- 数据容灾:任何服务器都有宕机的可能,我们同样可以通过主从复制功能提升Redis服务的可靠性;由于从服务器与主服务器数据保持同步,一旦主服务器宕机,可以立即将请求切换到从服务器,从而避免Redis服务中断。
- slaveof的主要流程:
- 从服务器向主服务器发送sync命令,请求同步数据
- 主服务器接收到sync命令请求,开始执行bgsave命令持久化数据到RDB文件,并且在持久化数据期间会将所有新执行的写入命令都保存到一个缓冲区。
- 从sync进化为psync:从服务器会记录已经从主服务器接收到的数据量(复制偏移量);而主服务器会维护一个复制缓冲区,记录自己已执行且待发送给从服务器的命令请求,同时还需要记录复制缓冲区第一个字节的复制偏移量。
- 每台Redis服务器都有一个运行ID,从服务器每次发送psync请求同步数据时,会携带自己需要同步主服务器的运行ID。主服务器接收到psync命令时,需要判断命令参数运行ID与自己的运行ID是否相等,只有相等才有可能执行部分重同步。
- 当持久化数据执行完毕后,主服务器将该RDB文件发送给从服务器,从服务器接收该RDB文件,并将文件的数据加载到内存。
- 主服务器将缓冲区的命令请求发送给从服务器。
- 每当主服务器接收到写命令请求时,都会将该命令请求按照Redis协议格式发送给从服务器,从服务器接收并处理主服务器发送过来的命令请求。
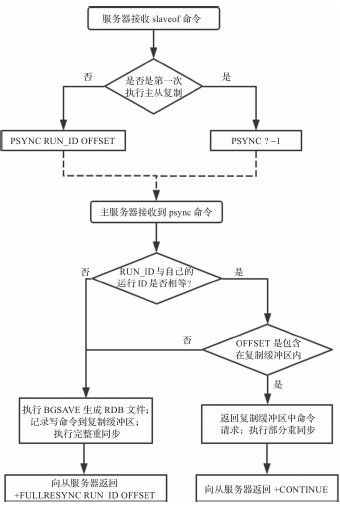
- psync的问题:要求RUN_ID必须相等且复制偏移量必须包含在复制缓冲区中,但从服务器重启或主从切换会导致无法执行部分重同步。psync2提出了两点优化:
- 持久化主从复制信息:Redis服务器关闭时,将主从复制信息(复制的主服务器RUN_ID与复制偏移量)作为辅助字段存储在RDB文件中;Redis服务器启动加载RDB文件时,恢复主从复制信息,重新同步主服务器时携带。
- 存储上一个主服务器复制信息:
/*初始化replid2为空字符串,second_replid_offset为-1;当主服务器发生故障,自己成为新的主服务器时,便使用replid2和second_replid_offset存储之前主服务器的运行ID与复制偏移量:*/
char replid2[CONFIG_RUN_ID_SIZE+1];
long long second_replid_offset;
void shiftReplicationId(void) {
memcpy(server.replid2,server.replid,sizeof(server.replid));
server.second_replid_offset = server.master_repl_offset+1;
changeReplicationId();
}
// 判断是否能执行部分重同步的条件
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset))
{
goto need_full_resync;
}
redisServer
- 文件:server.c
- 复制缓冲区:是一个先进先出的循环队列,当写入数据量超过缓冲区大小时,旧的数据会被覆盖。因此随着每次数据的写入,需要更新缓冲区中数据第一个字节的复制偏移量repl_backlog_off,同时记录下次写入数据时的索引位置repl_backlog_idx,以及当前缓冲区中有效数据长度repl_backlog_histlen。
struct redisServer {
……
/* Replication (master) */
// Redis服务器的运行ID,长度为CONFIG_RUN_ID_SIZE的随机字符串
char replid[CONFIG_RUN_ID_SIZE+1]; /* My current replication ID. */
char replid2[CONFIG_RUN_ID_SIZE+1]; /* replid inherited from master*/
long long master_repl_offset; /* My current replication offset */
long long second_replid_offset; /* Accept offsets up to this for replid2. */
int slaveseldb; /* Last SELECTed DB in replication output */
// 发送心跳包的周期,主服务器以此周期向所有从服务器发送心跳包
int repl_ping_slave_period; /* Master pings the slave every N seconds */
// 复制缓冲区,用于缓存主服务器已执行且待发送给从服务器的命令请求
char *repl_backlog; /* Replication backlog for partial syncs */
long long repl_backlog_size; /* Backlog circular buffer size */
// 复制缓冲区中存储的命令请求数据长度。
long long repl_backlog_histlen; /* Backlog actual data length */
// 复制缓冲区中存储的命令请求最后一个字节索引位置
long long repl_backlog_idx; /* Backlog circular buffer current offset,
that is the next byte will'll write to.*/
// 复制缓冲区中第一个字节的复制偏移量。
long long repl_backlog_off; /* Replication "master offset" of first
byte in the replication backlog buffer.*/
time_t repl_backlog_time_limit; /* Time without slaves after the backlog
gets released. */
time_t repl_no_slaves_since; /* We have no slaves since that time.
Only valid if server.slaves len is 0. */
int repl_min_slaves_to_write; /* Min number of slaves to write. */
int repl_min_slaves_max_lag; /* Max lag of <count> slaves to write. */
// 当前有效从服务器的数目。主服务器会记录每个从服务器上次心跳检测成功的时间repl_ack_time,并且定时检测当前时间距离repl_ack_time是否超过一定超时门限,如果超过则认为从服务器处于失效状态。
int repl_good_slaves_count; /* Number of slaves with lag <= max_lag. */
int repl_diskless_sync; /* Master send RDB to slaves sockets directly. */
int repl_diskless_load; /* Slave parse RDB directly from the socket.
* see REPL_DISKLESS_LOAD_* enum */
int repl_diskless_sync_delay; /* Delay to start a diskless repl BGSAVE. */
/* Replication (slave) */
char *masteruser; /* AUTH with this user and masterauth with master */
char *masterauth; /* AUTH with this password with master */
char *masterhost; /* Hostname of master */
int masterport; /* Port of master */
int repl_timeout; /* Timeout after N seconds of master idle */
// 当主从服务器成功建立连接之后,从服务器将成为主服务器的客户端,同样的主服务器也会成为从服务器的客户端。
client *master; /* Client that is master for this slave */
client *cached_master; /* Cached master to be reused for PSYNC. */
int repl_syncio_timeout; /* Timeout for synchronous I/O calls */
int repl_state; /* Replication status if the instance is a slave */
off_t repl_transfer_size; /* Size of RDB to read from master during sync. */
off_t repl_transfer_read; /* Amount of RDB read from master during sync. */
off_t repl_transfer_last_fsync_off; /* Offset when we fsync-ed last time. */
connection *repl_transfer_s; /* Slave -> Master SYNC connection */
int repl_transfer_fd; /* Slave -> Master SYNC temp file descriptor */
char *repl_transfer_tmpfile; /* Slave-> master SYNC temp file name */
time_t repl_transfer_lastio; /* Unix time of the latest read, for timeout */
// 当主从服务器断开连接时,该变量表示从服务器是否继续处理命令请求。
int repl_serve_stale_data; /* Serve stale data when link is down? */
// 表示从服务器是否只读(不处理写命令)
int repl_slave_ro; /* Slave is read only? */
int repl_slave_ignore_maxmemory; /* If true slaves do not evict. */
time_t repl_down_since; /* Unix time at which link with master went down */
int repl_disable_tcp_nodelay; /* Disable TCP_NODELAY after SYNC? */
int slave_priority; /* Reported in INFO and used by Sentinel. */
int slave_announce_port; /* Give the master this listening port. */
char *slave_announce_ip; /* Give the master this ip address. */
……
}
slaver
- 当Redis服务器接收到slaveof命令时,需要主动连接主服务器请求同步数据。
- 向主服务器发起连接请求是一个异步操作,在时间事件中执行。
- 变量repl_state表示的就是主从复制流程的进展(从服务器状态)
void replicaofCommand(client *c) {
//slaveof no one命令可以取消复制功能
if (!strcasecmp(c->argv[1]->ptr,"no") &&
!strcasecmp(c->argv[2]->ptr,"one")) {
} else {
server.masterhost = sdsnew(ip);
server.masterport = port;
server.repl_state = REPL_STATE_CONNECT;
}
addReply(c,shared.ok);
}
master
- 从服务器接收到slaveof命令会主动连接主服务器请求同步数据,主要流程有:
- 连接Socket;
- 发送PING请求包确认连接是否正确;
- 发起密码认证(如果需要);
- 通过REPLCONF命令同步信息;
- 发送PSYNC命令;
- 接收RDB文件并载入;
- 连接建立完成,等待主服务器同步命令请求。
哨兵
基本原理
- 概念:哨兵是Redis的高可用方案,可以在Redis Master发生故障时自动选择一个Redis Slave切换为Master,继续对外提供服务。
- 原理:哨兵通过与Master和Slave的通信,能够清楚每个Redis服务的健康状态。这样,当Master发生故障时,哨兵能够知晓Master的此种情况,然后通过对Slave健康状态、优先级、同步数据状态等的综合判
断,选取其中一个Slave切换为Master,并且修改其他Slave指向新的Master地址。- 需要多个哨兵:哨兵机制可以保证Redis服务不出现单点故障,那么首先哨兵不能成为单点。
- 需要奇数个哨兵:哨兵间投票选举leader从而决定由谁来执行切换操作。
代码流程
- 哨兵启动之后会先与配置文件中监控的Master建立两条连接,一条称为命令连接,另一条称为消息连接。并且与每个Redis Slave也建立同样的两条连接。(使用Redis的时间任务serverCron)
- 哨兵每次执行serverCron时,都调用sentinelTimer()函数,该函数会建立连接,并且定时发送心跳包并采集信息。该函数主要功能为:
- 建立命令连接和消息连接,消息连接建立后会订阅Redis服务的__sentinel__:hello频道。
- 在命令连接上每10s发送info命令进行信息采集;每1s在命令连接上发送ping命令探测存活性;每2s在命令连接上发布一条信息。
- info信息能够知道一个Redis Master有多少Slaves,然后在下一次执行sentinelTimer函数时会和所有的Slaves分别建立命令连接与消息连接。
- 通过订阅消息连接上的消息可以知道其他的哨兵,哨兵与哨兵之间只会建立一条命令连接。
- 信息内容包括:
- sentinel_ip:哨兵的IP
- sentinel_port:哨兵的端口
- sentinel_runid:哨兵的ID
- current_epoch:当前纪元(用于选举和主从切换)
- master_name:Redis Master的名称
- master_ip:Redis Master的IP
- master_port:Redis Master的端口
- master_epoch:Redis Master的配置纪元(用于选举和主从切换)
- 检测服务是否处于主观下线状态。
- 检测服务是否处于客观下线状态并且需要进行主从切换。
- 主从切换:Master处于客观下线状态,需要将其中一个Slave提升为Master,其他Slave从该提升的Slave继续同步数据。
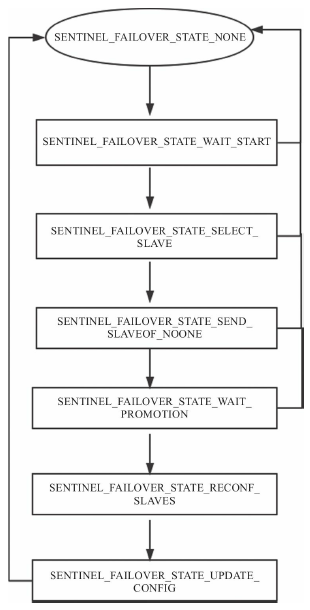
// 没有进行切换
#define SENTINEL_FAILOVER_STATE_NONE 0
// 当一个哨兵发现一台Master处于主观下线状态时切换至此状态,当前纪元加1,发送命令要求其他哨兵投票。
#define SENTINEL_FAILOVER_STATE_WAIT_START 1
// 选出了主哨兵(leader sentinel),切换为此状态,选择一台从服务器作为新的主服务器
/* 选择规则:
1. 如果该Slave处于主观下线状态,则不能被选中。
2. 如果该Slave 5s之内没有有效回复ping命令或者与主服务器断开时间过长,则不能被选中。
3. 如果slave-priority为0,则不能被选中(slave-priority可以在配置文件中指定。正整数,值越小优先级越高,当指定为0时,不能被选为主服务器)。
4. 在剩余Slave中比较优先级,优先级高的被选中;如果优先级相同,则有较大复制偏移量的被选中;否则按字母序选择排名靠前的Slave。
*/
#define SENTINEL_FAILOVER_STATE_SELECT_SLAVE 2
//将被选中的从服务器切换为主服务器
#define SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE 3
//等待被选中的从服务器上报状态
#define SENTINEL_FAILOVER_STATE_WAIT_PROMOTION 4
//将其他Slave切换为向新的主服务器要求同步数据
#define SENTINEL_FAILOVER_STATE_RECONF_SLAVES 5
//重置Master,将Master的IP:PORT设置为被选中从服务器的IP:PORT
#define SENTINEL_FAILOVER_STATE_UPDATE_CONFIG 6
- 主从切换完成之后,客户端和其他哨兵如何知道现在提供服务的Redis Master是哪一个呢?
- 答 :可以通过subscribe__sentinel__:hello频道,知道当前提供服务的Master的IP和Port。
- 执行切换的哨兵发生了故障,切换操作是否会由其他哨兵继续完成呢?
- 答 :执行切换的哨兵发生故障后,剩余哨兵会重新选主,并且重新开始执行切换流程。
- 故障Master恢复之后,会继续作为Master提供服务还是会作为Slave提供服务?
- 答 :Redis中主从切换完成之后,当故障Master恢复之后,会作为新Master的一个Slave来提供服务。
集群
基本原理
- 概念:集群提供数据自动分片到不同节点的功能,并且当部分节点失效后仍然可以使用。
- 分槽(slot):即如何决定某条数据应该由哪个节点提供服务。Redis将键空间分为了16384个slot,通过算法计算出每个key所属的slot。客户端可以请求任意一个节点,每个节点中都会保存所有16384个slot对应到哪一个节点的信息。
- 副本漂移:假设一对主从同时发生故障,则集群中的某些slot会处于不能提供服务的状态,从而导致集群失效。为某些主节点增加额外的从节点,当集群中有某个主从对出现单点问题后,额外的从节点会漂移给单点主节点做从节点。
- 分片迁移:增加一个新节点之后需要把一些分片迁移到新节点,或者当删除一个节点之后,需要将该节点提供服务的分片迁移到其他节点,甚至有些时候需要根据负载重新配置分片的分布。
主从切换(failover)
- 自动切换:集群之间会互相发送心跳包,心跳包中会包括从发送方视角所记录的关于其他节点的状态信息。切换流程如下(假设被切换的主节点为M,执行切换的从节点为S)。
- S先更新自己的状态,将自己声明为主节点。并且将S从M中移除。
- 由于S需要切换为主节点,所以将S的同步数据相关信息清除(即不再从M同步数据)。
- 将M提供服务的slot都声明到S中。
- 发送一个PONG包,通知集群中其他节点更新状态。
- 手动切换:当一个从节点接收到cluster failover命令之后,执行手动切换,流程如下
- 该从节点首先向对应的主节点发送一个mfstart包,通知主节点从节点要开始进行手动切换。
- 主节点会阻塞所有客户端命令的执行。之后主节点在周期性函数clusterCron中发送ping包时会在包头部分做特殊标记。
- 当从节点收到主节点的ping包并且检测到特殊标记之后,会从包头中获取主节点的复制偏移量。
- 从节点在周期性函数clusterCron中检测当前处理的偏移量与主节点复制偏移量是否相等,当相等时开始执行切换流程。
- 切换完成后,主节点会将阻塞的所有客户端命令通过发送+MOVED指令重定向到新的主节点。
通信数据包
- 共有10种,编号从0到9,编号10是包类型计数边界,代码中做判断使用。
//ping包,每个节点通过心跳包可以知道其他节点的当前状态并且保存到本节点状态中。
#define CLUSTERMSG_TYPE_PING 0
//pong包,在接收到ping包和meet包之后会作为回复包发送,当进行主从切换之后,新的主节点会向集群中所有节点直接发送一个pong包,通知主从切换后节点角色的转换。
#define CLUSTERMSG_TYPE_PONG 1
//meet包,当执行cluster meet ip port命令连接开启集群支持的节点之后,执行端会向ip:port指定的地址发送meet包,接建立之后,会定期发送ping包。
#define CLUSTERMSG_TYPE_MEET 2
//fail包,用来通知集群中某个节点处于故障状态
#define CLUSTERMSG_TYPE_FAIL 3
//publish包,用来发布消息
#define CLUSTERMSG_TYPE_PUBLISH 4
//failover授权请求包,当需要执行主从切换时请求集群中的其他节点向发送该包的节点授权
#define CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 5
//failover授权确认包,当一个主节点收到请求授权包后,会根据一定的条件决定是否给发送节点发送一
个failover授权包
/*
1. 请求授权包中的currentEpoch小于当前节点记录的currentEpoch,则不授权。
2. 已经授权过相同currentEpoch的其他节点,则不再授权。
3. 对同一个主从切换,上次授权时间距离现在小于2倍的nodetimeout(节点超时时间,在配置文件中指定),则不再进行授权。
4. 从所声明的所有slots的configEpoch必须大于等于所有当前节点记录的slot对应的configEpoch,否则不授权。
当通过上述所有条件后,接收节点才会发送failover授权包给发送节点。
*/
#define CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 6
//update包,用来更新集群中节点的配置信息
#define CLUSTERMSG_TYPE_UPDATE 7
//手动failover包,当在一个从节点输入cluster failover命令之后,该从节点会向对应的主节点发送mfstart包,提示主节点开始进行手动切换。
#define CLUSTERMSG_TYPE_MFSTART 8
//模块相关包
#define CLUSTERMSG_TYPE_MODULE 9
//计数边界
#define CLUSTERMSG_TYPE_COUNT 10