概述
Redis的特点
- 基于内存进行存储,且绝大部分命令处理是纯粹的内存操作。
- 单进程线程服务,避免了不必要的上下文切换,不存在同步操作。
- Redis6.0版本在处理网络数据的读写和协议解析时使用多线程I/O操作。
- 使用多路I/O复用模型,如select/poll/epoll等。
- 专用数据结构,增删改查简单。
- Redis6.0新特性
代码结构
- 基本数据结构
- sds.c:简单动态字符串
- intset.c:整数集合
- ziplist.c:压缩列表
- quicklist.c:快速链表
- dict.c:字典
- listpack.c&rax.c:Streams的底层实现结构
- 数据类型底层实现
- object.c:对象
- t_string.c:字符串
- t_list.c:列表
- t_hash.c:字典
- t_set.c&t_zset.c:集合及有序集合
- t_stream.c:数据流
- 数据库底层实现
- db.c:数据库的底层实现
- rdb.c&aof.c:持久化
- 客户端服务器实现
- ae.c&ae_epoll.c:事件驱动
- anet.c&networking.c:网络连接
- server.c:服务端程序
- redis-cli.c:客户端程序
- 其他实现
- replication.c:主从复制
- sentinel.c:哨兵
- cluster.c:集群
- 其他数据结构,如hyperloglog.c、geo.c等
- 其他功能,如pub/sub、Lua脚本
简单动态字符串(Simple Dynamic Strings,SDS)
基本定义
- 文件:sds.h/sds.c
- 用途:存储字符串和整型数据。
- 它兼容C语言标准字符串处理函数,且在此基础上保证了二进制安全。
- 二进制安全:二进制安全函数是指,在一个二进制文件上所执行的不更改文件内容的功能或者操作,其本质上将操作输入作为原始的、无任何特殊格式意义的数据流。
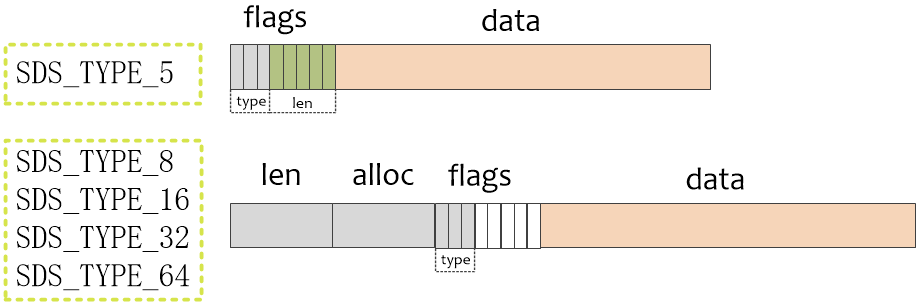
- SDS是一种TLV(Tag/Length/Value)格式的数据结构,其主要字段如下:
- flags :相当于Tag。标识当前结构体的类型,低3位用作标识位,除了sdshdr5以外高5位预留。
- len :相当于Length。表示buf中已占用字节数,根据flags的标识,长度有小于1字节、1字节、2字节、4字节、8字节五种。
- alloc :表示buf分配的字节数总长度,sdshdr5中没有此字段,长度和len相同。
- buf :相当于Value。是一个柔性数组,真正存储字符串的数据空间。
- 柔性数组:无需指定大小,通过malloc函数在堆上动态分配内存,只能被放在结构体的末尾。
- 因为柔性数组的地址和结构体是连续的,可以通过柔性数组的首地址偏移得到结构体首地址,进而能方便地获取其余变量。
- 对上层直接暴露指向柔性数组的指针而不是指向SDS的指针,从而上层可像读取C字符串一样读取SDS的内容。
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
// __attribute__ ((__packed__))关键字可以取消字节对齐,让结构体按照紧凑排列的方式占用内存。
struct __attribute__ ((__packed__))sdshdr5 {
// 在Redis6.0源码中,sdshdr5不被使用,但保留结构的定义。
unsigned char flags; /* 低3位存储类型, 高5位存储长度 */
char buf[];/*柔性数组,存放实际内容*/
};
struct __attribute__((__packed__))sdshdr8 {
uint8_t len; /* 已使用长度,用1字节存储 */
uint8_t alloc; /* 总长度,用1字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[];/*柔性数组,存放实际内容*/
};
struct __attribute__((__packed__))sdshdr16 {
uint16_t len; /*已使用长度,用2字节存储*/
uint16_t alloc; /* 总长度,用2字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[];/*柔性数组,存放实际内容*/
};
struct __attribute__((__packed__))sdshdr32 {
uint32_t len; /*已使用长度,用4字节存储*/
uint32_t alloc; /* 总长度,用4字节存储*/
unsigned char flags;/* 低3位存储类型, 高5位预留 */
char buf[];/*柔性数组,存放实际内容*/
};
struct __attribute__((__packed__))sdshdr64 {
uint64_t len; /*已使用长度,用8字节存储*/
uint64_t alloc; /* 总长度,用8字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[];/*柔性数组,存放实际内容*/
};
基本操作
创建字符串
sdsnewlen()
- sdsnewlen():根据字符串长度选择合适的类型,初始化统计值,返回指向字符串内容的指针。
// *init:指向字符串内容的指针;initlen:字符串长度
sds sdsnewlen(const void *init, size_t initlen) {
// 空指针,用于后续为SDS分配内存地址
void *sh;
// 用于返回值,指向buf的指针,其类型定义为typedef char *sds;
sds s;
// 根据字符串长度选择不同的类型
char type = sdsReqType(initlen);
// 空字符串通常在创建后会被添加,因此在试图创建sdshdr5的空字符串时会强制转为sdshdr8,以避免频繁的更新引发的扩容。
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
// 计算不同类型的头部所需长度
int hdrlen = sdsHdrSize(type);
// 指向Flag字段的指针
unsigned char *fp;
// 分配内存,+1是为了保存结束符'\0'
sh = s_malloc(hdrlen+initlen+1);
// 未能分配内存
if (sh == NULL) return NULL;
// 如果使用了SDS_NOINIT,则buf不进行初始化
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
// 清空所分配的内存区间
memset(sh, 0, hdrlen+initlen+1);
// 将s指向buf的起始点
s = (char*)sh+hdrlen;
// 将fp指向flags。s是柔性数组buf的指针,-1即指向flags
fp = ((unsigned char*)s)-1;
// 根据不同的类型进行初始化len/alloc/type字段
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
// 初始化buf字段
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
// 返回指向buf的指针
return s;
}
释放字符串
sdsfree()
- sdsfree():该方法通过对s的偏移,可定位到SDS结构体的首部,然后调用s_free释放内存。
void sdsfree(sds s) {
if (s == NULL) return;
// 直接释放内存
s_free((char*)s-sdsHdrSize(s[-1]));
}
sdsclear()
- sdsclear():该方法仅将SDS的len归零,此处已存在的buf并没有真正被清除,新的数据可以覆盖写,而不用重新申请内存,从而减少申请内存的开销。
void sdsclear(sds s) {
sdssetlen(s, 0); //统计值len归零
s[0] = '\0';//清空buf
}
拼接字符串
sdscatsds()
- sdscatsds():上层API,调用sdscatlen()实现字符串拼接。
sds sdscatsds(sds s, const sds t) {
return sdscatlen(s, t, sdslen(t));
}
sdscatlen()
- sdscatlen():调用sdsMakeRoomFor()对带拼接的字符串s容量做检查,并按需扩容。
// 将指针t的内容和指针s的内容拼接在一起,该操作是二进制安全的
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);//直接拼接,保证了二进制安全
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';//加上结束符
return s;
}
sdsMakeRoomFor()
- sdsMakeRoomFor():实现了扩容策略。
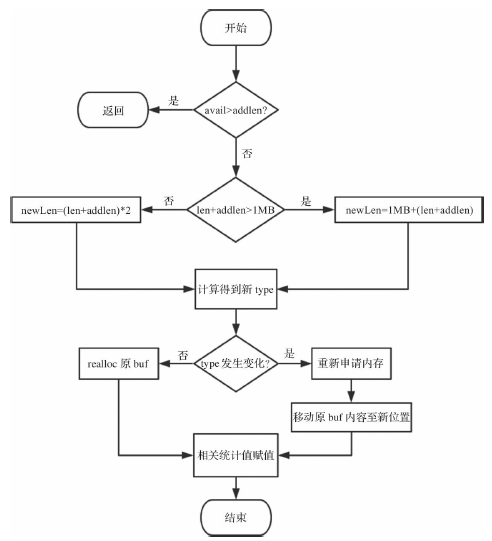
- 若sds中剩余空闲长度avail大于新增内容的长度addlen,直接在柔性数组buf末尾追加即可,无须扩容。
- 若sds中剩余空闲长度avail小于或等于新增内容的长度addlen,则分情况讨论:新增后总长度len+addlen小于1MB的,按新长度的2倍扩容;新增后总长度len+addlen大于1MB的,按新长度加上1MB扩容。
- 根据新长度重新选取存储类型,并分配空间。此处若无须更改类型,通过realloc扩大柔性数组即可;否则需要重新开辟内存,并将原字符串的buf内容移动到新位置。
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
// s[-1]即flags
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
// 无须扩容,直接返回
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
// SDS__MAX_PREALLOC这个宏的值是1MB
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
// type5的结构不支持扩容,所以这里需要强制转成type8
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
// 无须更改类型,通过realloc扩大柔性数组即可,注意这里指向buf的指针s被更新了
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
// 扩容后数据类型和头部长度发生了变化,此时不再进行realloc操作,而是直接按新长度重新开辟内存
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
// 将原buf内容移动到新位置
memcpy((char*)newsh+hdrlen, s, len+1);
// 释放旧指针
s_free(sh);
// 偏移sds结构的起始地址,得到字符串起始地址
s = (char*)newsh+hdrlen;
// 为falgs赋值
s[-1] = type;
// 为len属性赋值
sdssetlen(s, len);
}
// 为alloc属性赋值
sdssetalloc(s, newlen);
return s;
}
其他API
| 函数名称 |
作用 |
复杂度 |
| sdsempty |
创建一个只包含空字符串””的sds |
O(N) |
| sdsnew |
根据给定的C字符串,创建一个相应的sds |
O(N) |
| sdsnewlen |
创建一个指定长度的sds,接受一个指定的C字符串作为初始化值 |
O(N) |
| sdsdup |
复制给定的sds |
O(N) |
| sdsfree |
释放给定的sds |
O(1) |
| sdsupdatelen |
更新给定sds所对应的sdshdr的free与len值 |
O(1) |
| sdsMakeRoomFor |
对给定sds对应sdshdr的buf进行扩展 |
O(N) |
| sdscatlen |
将一个C字符串追加到给定的sds对应sdshdr的buf |
O(N) |
| sdscpylen |
将一个C字符串复制到sds中,需要依据sds的总长度来判断是否需要扩展 |
O(N) |
| sdscatprintf |
通过格式化输出形式,来追加到给定的sds |
O(N) |
| sdstrim |
对给定sds,删除前端/后端在给定的C字符串中的字符 |
O(N) |
| sdsrange |
截取给定sds,[start,end]字符串 |
O(N) |
| sdscmp |
比较两个sds的大小 |
O(N) |
| sdssplitlen |
对给定的字符串s按照给定的sep分隔字符串来进行切割 |
O(N) |
跳跃表
基本定义
- 文件:t_zset.c
- 概念:是一种能确保对动态集合search,insert以及delete等操作的时间复杂度在O(lgn)的前提下,实现比较简单,还能比较方便的进行范围查询的数据结构。
- 用途:应用于有序集合的底层实现(Redis中另一种实现方式为压缩列表)
- zset插入第一个元素时,会判断下面两种条件,满足任一条件Redis就会采用跳跃表作为底层实现,否则采用压缩列表作为底层实现方式。
- zset-max-ziplist-entries的值是否等于0;
- zset-max-ziplist-value小于要插入元素的字符串长度。
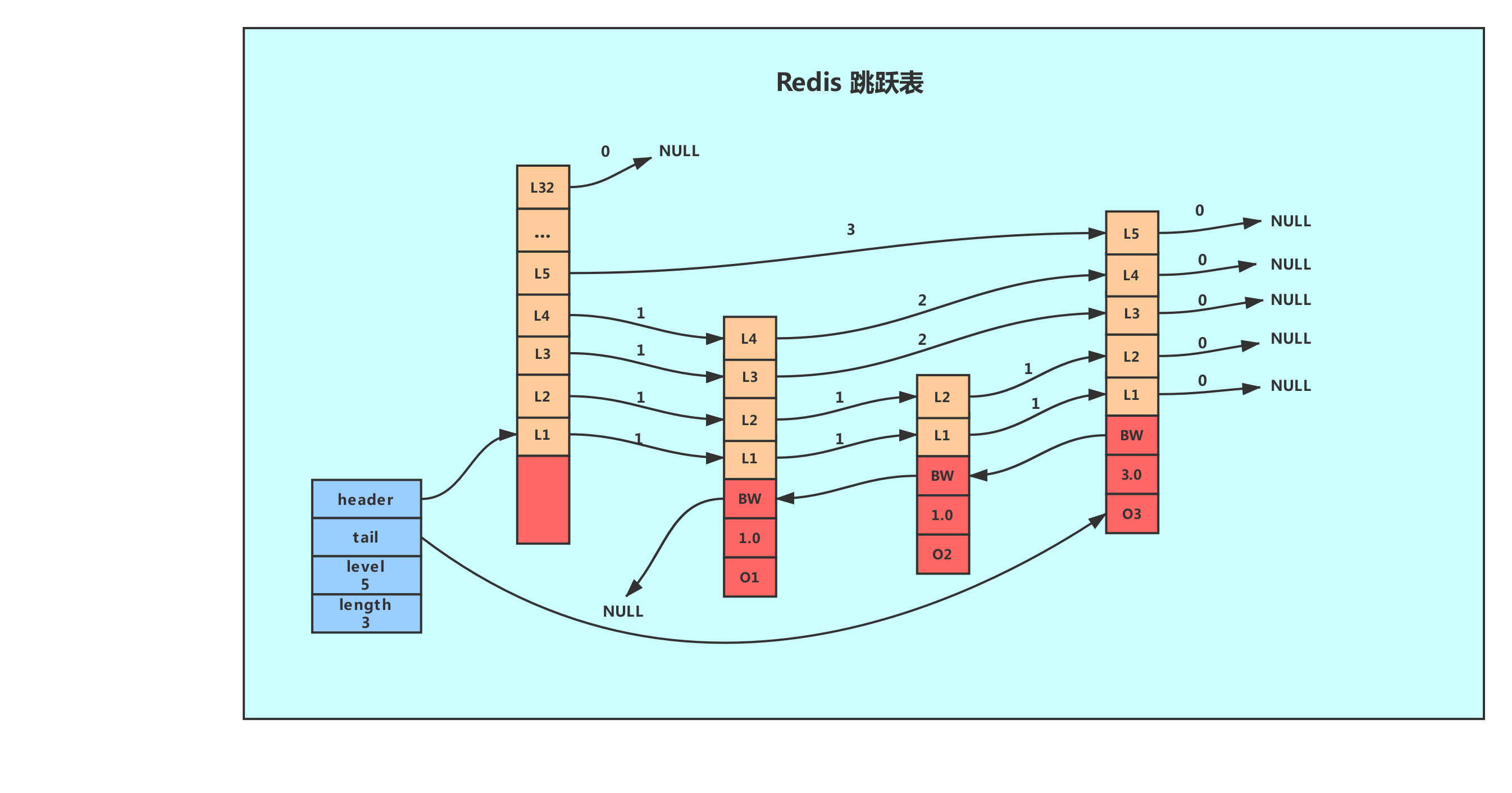
- 性质:
- 由很多层构成。
- 有一个头节点,头节点中有一个32层的结构,每层的结构包含指向本层的下个节点的指针,指向本层下个节点中间所跨越的节点个数为本层的跨度(span)。
- 除头节点外,层数最多的节点的层高为跳跃表的高度(level)。
- 每层都是一个有序链表,数据递增。
- 除头节点外,一个元素在上层有序链表中出现,则它一定会在下层有序链表中出现。
- 跳跃表每层最后一个节点指向NULL,表示本层有序链表的结束。
- 跳跃表拥有一个tail指针,指向跳跃表最后一个节点。
- 最底层的有序链表包含所有节点,最底层的节点个数为跳跃表的长度(length)(不包括头节点)。
- 每个节点包含一个后退指针,头节点和第一个节点指向NULL;其他节点指向最底层的前一个节点。
- 实现:Redis的跳跃表由zskiplistNode和zskiplist两个结构定义,其中zskiplistNode结构用于表示跳跃表节点,而zskiplist结构则用于保存跳跃表节点的相关信息,比如节点的数量、指向表头节点和表尾节点的指针等。
zskiplistNode
typedef struct zskiplistNode {
// 用于存储字符串类型的数据。
sds ele;
// 用于存储排序的分值。所有节点的分值是按从小到大的方式排序的,当有序集合的成员分值相同时,节点会按ele的字典序进行排序。
double score;
// 后退指针,指向当前节点最底层的前一个节点,在程序从表尾向表头遍历时使用,每次只能后退一个节点。
struct zskiplistNode *backward;
// 结构体的柔性数组。每个节点的数组长度不一样,在生成跳跃表节点时,随机生成一个1~32的值,值越大出现的概率越低。
struct zskiplistLevel {
// 指向本层下一个节点,尾节点的forward指向NULL。
struct zskiplistNode *forward;
// forward指向的节点与本节点之间的元素个数。span值越大,跳过的节点个数越多。
unsigned int span;
} level[];
} zskiplistNode;
zskiplist
typedef struct zskiplist {
// header:指向跳跃表头节点。
// tail:指向跳跃表尾节点。
struct zskiplistNode *header, *tail;
// length:跳跃表长度,表示除头节点之外的节点总数。
unsigned long length;
// level:跳跃表的高度。
int level;
} zskiplist;
基本操作
创建跳跃表
zslRandomLevel()
- 节点层高:节点层高的最小值为1,最大值是ZSKIPLIST_MAXLEVEL,Redis6中为32。
// server.h
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
// t_zset.c
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
E=1×(1−p)+2×p(1−p)+3×p2(1−p)+…=(1−p)i=1∑+∞ipi−1=1−p1
zslCreateNode()
- 在创建跳跃表节点时,待创建节点的层高、分值、member等都已确定,需要申请内存来建立节点。
- 一个节点占用的内存大小为zskiplistNode的内存大小与level个zskiplistLevel的内存大小之和。
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
zslCreate()
zskiplist *zslCreate(void) {
int j;
// 创建跳跃表结构体对象zsl
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
// 跳跃表层高初始化为1,长度初始化为0
zsl->level = 1;
zsl->length = 0;
// 将zsl的头节点指针指向新创建的头节点
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 创建头结点,头节点是第一个插入的节点,不存储有序集合的member信息。其level数组的每项forward都为NULL,span值都为0。
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
// 跳跃表尾节点指向NULL。
zsl->tail = NULL;
return zsl;
}
插入节点
- 插入节点的步骤:
- 查找要插入的位置
- 调整跳跃表高度
- 插入节点
- 调整backward
zslInsert()
/** 将新的节点插入到zskiplist中。在调用该函数之前,由调用者确保该成员在zskiplist中不存在 **/
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
/* update数组保存了新节点在插入之后各个level的紧邻的前边的节点 */
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
/* rank数组保存在新节点插入之后所在位置的各个level的前面紧邻节点在整个跳跃表中的排位,用于更新各个level的前面紧邻节点的跨度和新节点到后面紧邻节点的跨度 */
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
/** 如果!isnan(score)为0,那么将记录相关的错误信息,exit(1)退出程序 **/
serverAssert(!isnan(score));
// x为跳跃表的头节点
x = zsl->header;
/** 下面的for循环是为了确定新的zskiplistNode节点应该插入的位置的前面的节点 x **/
/** 按照在跳跃表中查找给定节点的顺序,应该是按照forward和down的顺序进行查找。首先是从最高层开始向后进行查找,如果当前节点的forward指针指向的节点的score小于给定的score或者说forward指向的节点的score等于给定的score但是forward指向的节点的ele的字典序小于给定的ele,应该继续向后进行查找,否则应该向下进行查找,对应于redis中的实现,zskiplist实现中,应该将层级减 1。在跳跃表中,在较高的层出现的zskiplistNode在较低的层肯定会出现;反之却不一定 **/
/** 注意这里的 i 是从zsl->level-1开始的,而不是从最大的ZSKIPLIST_MAXLEVEL开始的 **/
for (i = zsl->level-1; i >= 0; i--) {
/** 初始化每一层的rank。如果是最高的一层,则初始化为0;如果不是最大的level,则证明是由上一层级down下来的,应该初始化为上一层的rank **/
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
/** x代表在第 i 层要插入的节点的backward指针指向的节点;每层或者都不一样或者也有可能是相同的 **/
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
/** update保存了新插入的节点位置在第 i 层的前向节点 **/
update[i] = x;
}
level = zslRandomLevel();
/** 如果随机产生的新的层级大于当前的zsl中保存的level(当前zsl的最大层级),那么新的层级的backward节点全部指向zsl->header;此时当然在update> 中保存的也是update[i](i > zsl)应该是zsl->header; **/
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
/** 只是暂时的一个初始化,后面会进行相应的修改 **/
update[i]->level[i].span = zsl->length;
}
/** 新插入的zskiplistNode的层大于现有的zsl->level,更改现有的zsk->level **/
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
/* 更新新插入的节点在每层的forward节点指向的节点 */
x->level[i].forward = update[i]->level[i].forward;
/* 更新新插入的节点所在位置前面紧邻节点的forward指向新插入的节点 */
update[i]->level[i].forward = x;
/* 改变由于插入新的zskiplistNode导致的跨度的变化 */
/** rank[0] 代表了要插入的 zskiplistNode 在实际的链表中的排位,rank[i]代表了在相应的层级的排位 **/
/** 跨度如果不好明白的话,可以画图理解 **/
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* 如果新插入的节点的level小于原来的zsl->level,那么那些大于新插入节点level的level并没有指针指向新插入的节点,此时只需简单的将其跨度增加 1 即可 */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
/** header 节点的forward节点的backward节点不再指向header,而是指向NULL **/
x->backward = (update[0] == zsl->header) ? NULL : update[0];
/** 考虑到将新的zskiplistNode节点添加到最后一个节点的情况 **/
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
删除节点
- 删除节点的步骤:
- 查找需要更新的节点
- 设置span和forward。
zslDelete()
/* node 指向要删除的节点的指针的指针;如果不需要返回被删除的节点,那么直接将该参数置为NULL即可,如果希望返回被删除的节点,那么该参数不能为空
*/
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
/* 确定要删除的节点在每一层的前面的紧邻节点 */
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
/** update保存在该节点在每一层级的前向节点 **/
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
/* unlink from current zskiplist */
zslDeleteNode(zsl, x, update);
/* free the node dirctely */
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
/* node 指向要删除的节点的指针的指针;如果不需要返回被删除的节点,那么直接将该参数置为NULL即可,如果希望返回被删除的节点,那么该参数不能为空
*/
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
/* 确定要删除的节点在每一层的前面的紧邻节点 */
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
/** update保存在该节点在每一层级的前向节点 **/
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
/* unlink from current zskiplist */
zslDeleteNode(zsl, x, update);
/* free the node dirctely */
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}